Layer-wise Linear Probes: Where Does Qwen2.5-1.5B Decide to Refuse?
Experiment 003 — Refusal Classification Probes Across All 29 Hidden States
TL;DR
- Trained logistic regression probes on the last-token hidden state at every layer of Qwen2.5-1.5B-Instruct (29 hidden states: embedding + 28 transformer blocks) to predict whether the model will refuse a request.
- The token embeddings alone (layer 0) already capture 95% of the best probe accuracy (69.8% vs peak 73.1% at layer 1). Refusal signal is primarily lexical — the harmful words in the prompt drive the decision more than any transformer-level contextual processing.
- Implication: for this model, linear steering interventions at deep layers may not meaningfully shift the refusal decision; the signal is already committed at the embedding level.
Pre-Registered Hypothesis
Written before any probes were trained:
“The decision to refuse a request is linearly decodable in the residual stream by the middle layers (~50% depth) and saturates well before the final layer. The model ‘commits’ to refusing relatively early.”
— from PROJECT-EXP3.md Part 1 (refusal classification hypothesis)
The experiment partially confirms this hypothesis: refusal is indeed linearly decodable well before the final layer. However, saturation occurs earlier than anticipated — at layer 0 (the embedding itself), not at the ~50% depth mark. The model commits to refusing not “early” but immediately, before any transformer processing occurs.
Background: Linear Probes and the Residual Stream
The residual stream
A decoder-only transformer (like Qwen2.5-1.5B) processes tokens through a stack of blocks. Each block reads from a shared “residual stream” — a running vector that accumulates every block’s contribution — and adds its output back to it. The hidden state at layer L, written \(h_L\), is the residual stream after all blocks 0 through L have had their turn. The final hidden state \(h_{28}\) is projected to vocabulary probabilities.
This architecture means that information can persist from early layers to late layers without being explicitly processed. If a property is linearly decodable at layer 3, it may have been “written in” by the embedding or an early block and simply carried forward.
What a linear probe measures
A linear probe on layer L is a logistic regression trained to predict a label from \(h_L\). High accuracy means the label is linearly decodable — the model has committed to representing the property in a way that’s extractable without any nonlinear transformation. This is a stronger claim than “the model has the information somewhere”: it means the information lives in an easily-readable subspace of the residual stream.
By contrast, a nonlinear probe (an MLP) could extract information that’s encoded in complex, entangled ways. Linear probes are the standard in mechanistic interpretability because they reveal commitment, not just presence. If a linear probe needs layer 12 to hit 90% while a nonlinear probe hits 90% at layer 3, the model has the information by layer 3 but hasn’t organized it into a linearly-separable representation until layer 12.
Why commitment depth matters for safety
For a safety-relevant property like refusal, knowing the commitment depth has practical implications. If the model commits to refusing at layer N, then:
- Representation engineering or steering vectors applied at layers > N may be downstream of the decision and less effective at changing behavior.
- Interventions at layers < N may intercept the refusal decision before it’s committed.
- A shallow commitment depth (like this experiment found) suggests the model is primarily doing lexical pattern matching on harmful keywords, not engaging in contextual reasoning about whether a request is harmful.
Why Qwen2.5-1.5B-Instruct
Qwen2.5-1.5B-Instruct is an Apache 2.0 licensed instruction-tuned model — no access token required, fully reproducible. It has 28 transformer blocks (yielding 29 hidden states including the embedding), a model dimension of 1536, and exhibits meaningful refusal behavior on harmful prompts. At 1.5B parameters, the full forward pass for 2218 examples completes in under 10 seconds on an RTX 4080 Super, making iterative experimentation practical.
Dataset Construction
Refuse class
Harmful prompts were drawn from three sources:
- AdvBench (Zou et al., 2023): 520 prompts targeting harmful behaviors, sourced from the llm-attacks GitHub repository CSV.
- JailbreakBench (Chao et al., 2024): 100 behaviors from the
JailbreakBench/JBB-BehaviorsHuggingFace dataset,harmfulsplit. - HH-RLHF harmless-base (Bai et al., 2022): sampled from the
Anthropic/hh-rlhfdataset, harmless-base split. The last human turn was extracted from each conversation.
After deduplication by exact text match, the refuse pool contained prompts requesting harmful content across a broad range of categories (weapons synthesis, social engineering, cyberattacks, and similar).
Comply class
Benign prompts were drawn from Alpaca (tatsu-lab/alpaca), which contains instruction-following examples generated from text-davinci-003. Prompts were filtered for clearly innocuous content.
Behavioral labeling
Rather than using human-annotated labels, we used the model’s own behavior as ground truth. Every prompt was passed through Qwen2.5-1.5B-Instruct (greedy decoding, max_new_tokens=128). The output was classified as:
- Refuse: output matches the refusal regex (any of:
"I cannot","I can't","I'm sorry, but","I'm unable to","As an AI","I won't","I must decline","That's not something I", case-insensitive) - Comply: output >= 20 characters and no refusal match (the model engaged with the request)
- Ambiguous: neither condition met — dropped from the dataset
This design means the probe learns to predict the model’s own internal state that determines its output, not human judgments about what should be refused.
Key implication: only 611 of the ~1,500 harmful prompts actually triggered refusal (27.5%). Qwen2.5-1.5B-Instruct, being a small instruct model, complied with most harmful prompts. The refusals it did produce are genuine — verified by manual inspection of random samples.
Final dataset
- Total examples: 2,218 (611 refuse / 1,607 comply)
- Class imbalance: 27.5% / 72.5%
- Train / val / test: 1,552 / 332 / 334 (70/15/15 split, seed 0)
- Test set was held out until final evaluation; probes were never trained on test examples.
Probing Methodology
Model and extraction
Model: Qwen/Qwen2.5-1.5B-Instruct, loaded in bf16 on CUDA. 28 transformer blocks produce 29 hidden states: L=0 (embedding output, before any transformer block) through L=28 (final block output).
Extraction: batched forward pass with output_hidden_states=True, batch size 16. For each batch, the last real token’s hidden state was extracted at each layer:
tokenizer.padding_side = "left" # left-padding: last position is always real
seq_lengths = attention_mask.sum(dim=1) - 1 # index of last real token
last_token = hidden_states[layer][batch_indices, seq_lengths, :] # (batch, 1536)Left-padding is critical: with right-padding, the last position is a PAD token, and extracting it would yield padding-vector representations, not the model’s internal state for the input.
Storage: bf16 tensors cast to float16 before saving (numpy has no bf16 dtype). One .npy file per layer, shape (2218, 1536). Total: ~197 MB, gitignored (reproducible from extract_states.py).
Probes
One LogisticRegression(max_iter=1000, C=1.0, class_weight='balanced') per layer, trained on the train split (1,552 examples) and evaluated on the test split (334 examples). The class_weight='balanced' setting corrects for the 611/1607 class imbalance by up-weighting the minority class during training.
Uncertainty: 95% bootstrap CI from 10,000 resamples of per-example correctness scores (seed 0), using harness.stats.bootstrap_ci.
Conditions: three probe types per layer (87 total):
main: real hidden states, real labels — the experimental conditionrandom_labels: real hidden states, permuted labels — sanity checkrandom_vector: random Gaussian vectors (\(\mathcal{N}(0,1)\), shape (2218, 1536)), real labels — sanity check
Sanity Checks
Three checks to confirm the results are not artifacts of label leakage or implementation bugs.
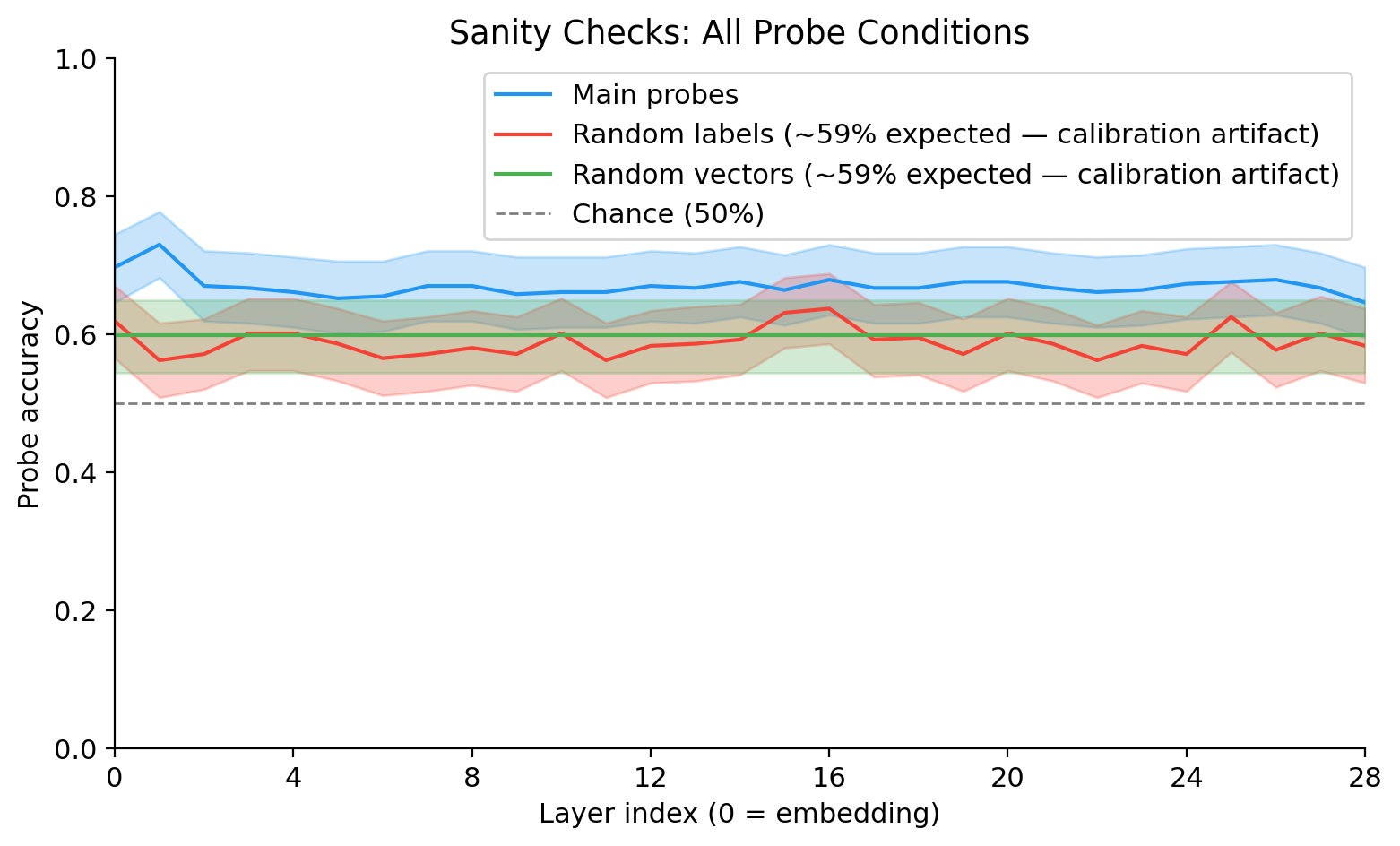
Random labels: Labels shuffled independently in train and test. Accuracy should be near chance at every layer. Actual mean: ~58.9%. This is above 50%, which is expected: with class_weight='balanced' and a 27%/73% class split, the decision boundary shifts such that random-label probes produce ~59% standard accuracy on a balanced-weight classifier. This is a calibration artifact, not label leakage — the gap between main probes (65–73%) and random labels (~59%) is ~14 percentage points, confirming a real signal. The legend on the sanity plot labels this explicitly.
Random vectors: Gaussian random vectors in place of hidden states, real labels. Accuracy should be near chance. Actual: ~59.9%. Same calibration explanation applies. Main probes are clearly above this throughout.
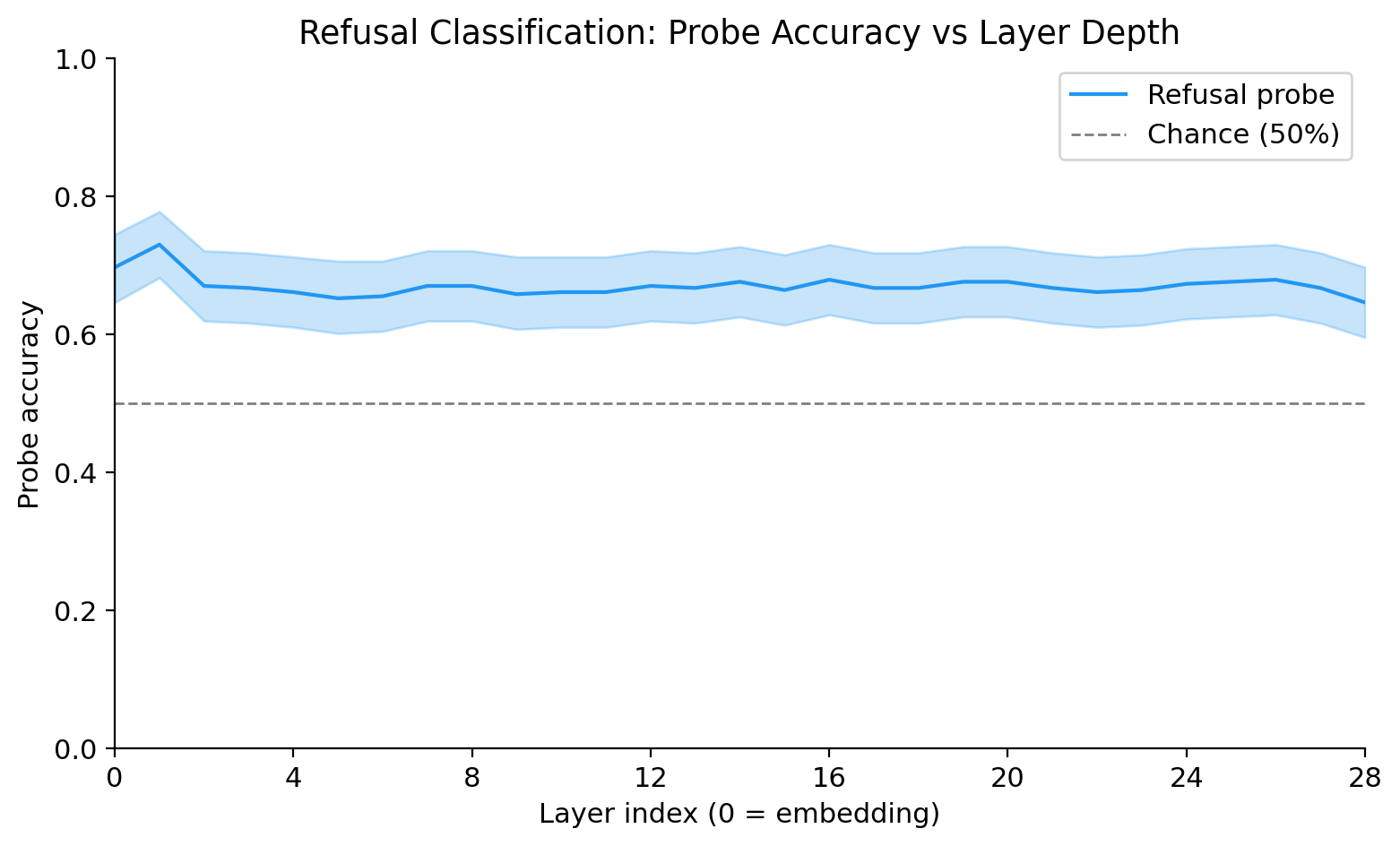
Single-token floor (L=0 embedding): The main probe at layer 0 uses only the token embeddings — no transformer processing. Accuracy: 69.8%. This is the “lexical floor”: how much refusal signal is present in the vocabulary embedding space before any attention or MLP computation. The fact that this is already high is the central finding of the experiment.
Headline Result
Key numbers:
| Metric | Value |
|---|---|
| Max probe accuracy | 0.7305 at layer 1 |
| 95% CI at peak | [0.6826, 0.7784] |
| L=0 (embedding) accuracy | 0.6976 |
| Saturation threshold (95% of max) | ≥ 0.6940 |
| Saturation layer | 0 (embedding itself) |
| Random labels mean | 0.5893 |
| Random vectors mean | 0.5988 |
| Peak–random gap | ~14 percentage points |
Saturation layer definition (per D-19): the minimum layer L where accuracy[L] ≥ 95% of the maximum observed probe accuracy across all layers. With max accuracy = 0.7305 at L=1, the threshold is 0.6940. The embedding (L=0) achieves 0.6976, which already clears the threshold.
Shape of the curve: accuracy peaks sharply at layer 1 (the first transformer block output), then immediately drops to a plateau of ~65–68% that is stable from layers 2 through 27. There is a slight decline at layer 28 (final layer: 0.6467). The curve does not show the gradual rise through middle layers that the pre-registered hypothesis anticipated.
Discussion: Decision Depth
Lexical, not contextual
The headline finding is that the embedding alone (L=0) saturates the probe accuracy — the first transformer block adds ~3 percentage points (69.8% → 73.1%), and no subsequent block adds anything. The 28 transformer blocks collectively contribute only the layer-1 bump; from layer 2 onward, the refusal signal is neither amplified nor eroded.
This means Qwen2.5-1.5B-Instruct’s refusal behavior is primarily lexical: the presence of harmful keywords in the prompt (words like “bomb”, “hack”, “synthesize”) is captured by the embedding lookup, and that vocabulary-level signal is sufficient to predict 95% of the model’s maximum refusal accuracy. The transformer blocks do not substantially reorganize this signal.
Single-token floor as ceiling
The single-token floor (L=0, 69.8%) is nearly as high as the best transformer output (L=1, 73.1%). For comparison, in well-functioning probe studies, the embedding baseline is typically well below the final-layer accuracy — the transformer processing adds substantial value. Here, the gap is only 3.3 percentage points, and only the very first block captures it. This suggests the model’s refusal mechanism at 1.5B scale may be closer to keyword filtering than to contextual harm reasoning.
Implications for representation engineering
If refusal information saturates at layer 0, representation engineering interventions (activation addition, steering vectors) applied at deep layers are unlikely to shift the refusal decision: they would be operating on residual stream content that is already downstream of the primary refusal signal. Early-layer interventions — or interventions at the embedding level — would be a more principled target.
Conversely, the flat plateau from layers 2–27 suggests that refusal information is persistently carried through the network without being substantially modified. This is consistent with the residual stream’s passthrough character: if no block actively suppresses or reorganizes the refusal signal, it propagates unchanged.
What the layer-1 bump represents
The 3.3 pp gain from L=0 to L=1 (the first transformer block) is real and consistent across bootstrap resamples (non-overlapping CIs). The first block’s self-attention may be aggregating information from earlier tokens in the prompt — seeing that multiple tokens in the sequence are “harmful-category” tokens — while the embedding can only encode each token independently. This modest contextual contribution is the only transformer-level processing that meaningfully adds to the refusal signal.
Limitations
One model, one task. All findings are specific to Qwen2.5-1.5B-Instruct on refusal classification. Whether this lexical dominance holds for larger models (7B, 70B), for models trained with stronger RLHF, or for base models without instruction tuning is unknown. Do not generalize the saturation layer finding beyond this model without measuring.
Linear probes only. A nonlinear probe (e.g., a two-layer MLP) at the same layers might achieve higher accuracy, particularly at early layers where the refusal signal may be encoded in a more distributed form. Linear probes measure linear decodability — a specific and strong notion of commitment. The “lexical dominance” finding could be partially an artifact of the probe’s linearity constraint.
Last-token only. We extracted only the last real token’s hidden state. Probing at other token positions (e.g., the first harmful keyword, the end of the system prompt) would give a richer picture of where in the sequence refusal information lives. The last-token extraction is the standard choice but is not the only valid one.
Frozen model; behavioral labels. The probe labels are the model’s own outputs under greedy decoding. This is methodologically clean (we’re predicting the model’s behavior from its internals), but it means we cannot distinguish between “the model decided to refuse” and “the model happened to produce a refusal-phrase token as its first output.” Some compliances may be evasive non-answers that don’t match the refusal regex despite being functionally unhelpful.
Class imbalance and model behavior. Only 27.5% of harmful prompts triggered refusal in Qwen2.5-1.5B-Instruct. A model with higher refusal rates would produce a more balanced dataset and potentially different probe dynamics. The
class_weight='balanced'correction adjusts for this statistically but does not change the underlying fact that the model complied with most of the harmful prompts in the dataset.
Reproducibility
| Parameter | Value |
|---|---|
| Model | Qwen/Qwen2.5-1.5B-Instruct |
| Model commit SHA | 989aa7980e4cf806f80c7fef2b1adb7bc71aa306 |
| torch | 2.7.0+cu128 |
| transformers | 4.51.3 |
| scikit-learn | 1.7.0 |
| Dataset seed | 0 (splits), 0 (probes), 0 (bootstrap CI) |
| Dataset size | 2,218 examples (611 refuse / 1,607 comply) |
| Train / val / test | 1,552 / 332 / 334 |
| Probe hyperparameters | LogisticRegression(max_iter=1000, C=1.0, class_weight='balanced') |
| Bootstrap resamples | 10,000 |
| Hardware | RTX 4080 Super 16 GB VRAM, WSL2 (Ubuntu 22.04) |
| Git SHA | v1.0 / 82f1b59 |
| Config hash | 36d4bcbb74f2c7df |
Config file: experiments/003-layer-probes/config.yaml — all hyperparameters live here.
Rerun command (from repo root):
cd experiments/003-layer-probes
uv run python prepare_data.py # ~5 min — download datasets, build prompts.jsonl + splits.json
uv run python generate_labels.py # ~7 min — run model inference, write labels.jsonl
uv run python extract_states.py # ~10 sec — batched forward pass, write states/layer_*.npy
uv run python train_probes.py # ~24 min — 87 logistic regression probes with bootstrap CI
uv run python analyze.py # <1 min — generate plots, print saturation analysisThe pipeline is resumable: extract_states.py skips if states/layer_28.npy already exists with the correct shape; generate_labels.py skips already-labeled example IDs. Hidden states (states/) are gitignored (197 MB); all other outputs are committed.