Quantization Quality Cliff: How Much Does Compression Cost?
Experiment 001 — Qwen2.5-7B-Instruct across Q8_0, Q5_K_M, Q4_K_M, Q3_K_M
- The pre-registered hypothesis was falsified. Math (GSM8K) did not degrade earlier or more sharply than factual QA. GSM8K was essentially flat across Q8_0 → Q3_K_M (0.905 → 0.885, no pairwise comparison reached significance). TriviaQA produced the only statistically significant quality drop, at Q3_K_M (−3.2pp vs Q8_0, 95% CI [0.8, 5.7], p=0.011).
- “Q4 is fine” is supported on 2 of 3 tasks tested. Q4_K_M is statistically indistinguishable from Q8_0 on reasoning (GSM8K, diff = 0.000), factual QA (TriviaQA, diff = +1.2pp, p=0.24), and structured extraction (diff = −0.1pp, p=0.79). The only cliff observed is between Q4_K_M and Q3_K_M, and only on TriviaQA.
- Structured extraction (3-field F1: name, category, urgency) is also flat across quants at ~61% — the model handles JSON generation equivalently well at every quant level we tested. Free-form
requested_actionwas excluded from grading because the gold is paraphrased prose with no canonical string to target (see Limitations).
Hypothesis
Pre-registered before running the experiment:
Quality degradation from quantization is non-uniform across task types. Tasks requiring multi-step reasoning (math) degrade earlier and more sharply than tasks requiring single-pass retrieval (factual QA).
Implications:
- If true: The “Q4 is fine” folklore is overgeneralized. Q4 is fine for some tasks; for reasoning workloads, Q5 or Q8 is worth the VRAM cost.
- If false: Quantization degradation is approximately uniform — equally useful, since it would justify the folklore across task types.
Methodology
Model
Qwen2.5-7B-Instruct from bartowski/Qwen2.5-7B-Instruct-GGUF on HuggingFace. SHA-256 of each GGUF file recorded in models/SHA256SUMS at download time.
Hardware and Software
- GPU: NVIDIA RTX 4080 Super (16 GB VRAM)
- OS: Windows 11, WSL2 (Ubuntu 22.04)
- Inference backend: llama-cpp-python 0.3.22 (cu124 wheel)
- Python: 3.11, managed via
uv
Quantization Levels Tested
| Quant level | Bits per weight (bpw) | File size (approx.) |
|---|---|---|
| Q8_0 | 8.5 | ~7.5 GB |
| Q5_K_M | 5.7 | ~5.0 GB |
| Q4_K_M | 4.8 | ~4.4 GB |
| Q3_K_M | 3.9 | ~3.5 GB |
FP16 (16.0 bpw) was excluded: the 15 GB GGUF exhausts the 16 GB VRAM budget when combined with KV-cache overhead. Q8_0 serves as the highest-quality k-quant reference; lower quant levels are compared to it using paired bootstrap tests.
Tasks
Three tasks were selected to stress different aspects of model capability:
GSM8K (math reasoning): 200 problems sampled from the test set using seeds [0, 1, 2]. Metric: exact match on the final numeric answer (extract number after #### in the gold answer; extract the last number in model output). Multi-step chains of arithmetic — errors compound.
TriviaQA rc.nocontext (factual QA): 200 questions sampled from the validation set using the same seeds, no retrieval context provided. Metric: normalized exact match (lowercase, strip punctuation, strip leading articles). Single-pass fact recall — errors do not compound.
Structured Extraction (JSON): 200 synthetic customer support emails, each requiring extraction of {customer_name, issue_category, urgency, requested_action} into strict JSON. Dataset generated once with gpt-4o-mini (~$0.50); first 50 examples hand-validated. Metric: field-wise F1 averaged over 4 fields.
Inference Settings
All settings held constant across all quant conditions:
temperature = 0.0 # greedy, deterministic
context_length = 4096
n_gpu_layers = -1 # full GPU offload
max_tokens = 512 # GSM8K
max_tokens = 64 # TriviaQA
max_tokens = 256 # ExtractionThe same prompt template (defined in prompts.py) was used across all quant levels.
Statistical Approach
- Per-condition CI: 10,000 bootstrap resamples over the 200 evaluations per (quant, task, seed) combination. Reported as 95% CI.
- Pairwise comparisons: Paired bootstrap test — each quant level vs Q8_0 (highest-quality k-quant reference) — using the same 200-item score arrays.
mean_diff = mean(Q8_0 - quant); positive values indicate Q8_0 is better. Seed fixed at 42 for all bootstrap calls. - Seeds: 3 seeds (
[0, 1, 2]) vary only sample selection, not model evaluation. Greedy decoding is deterministic given a fixed model.
Results — Headline Chart
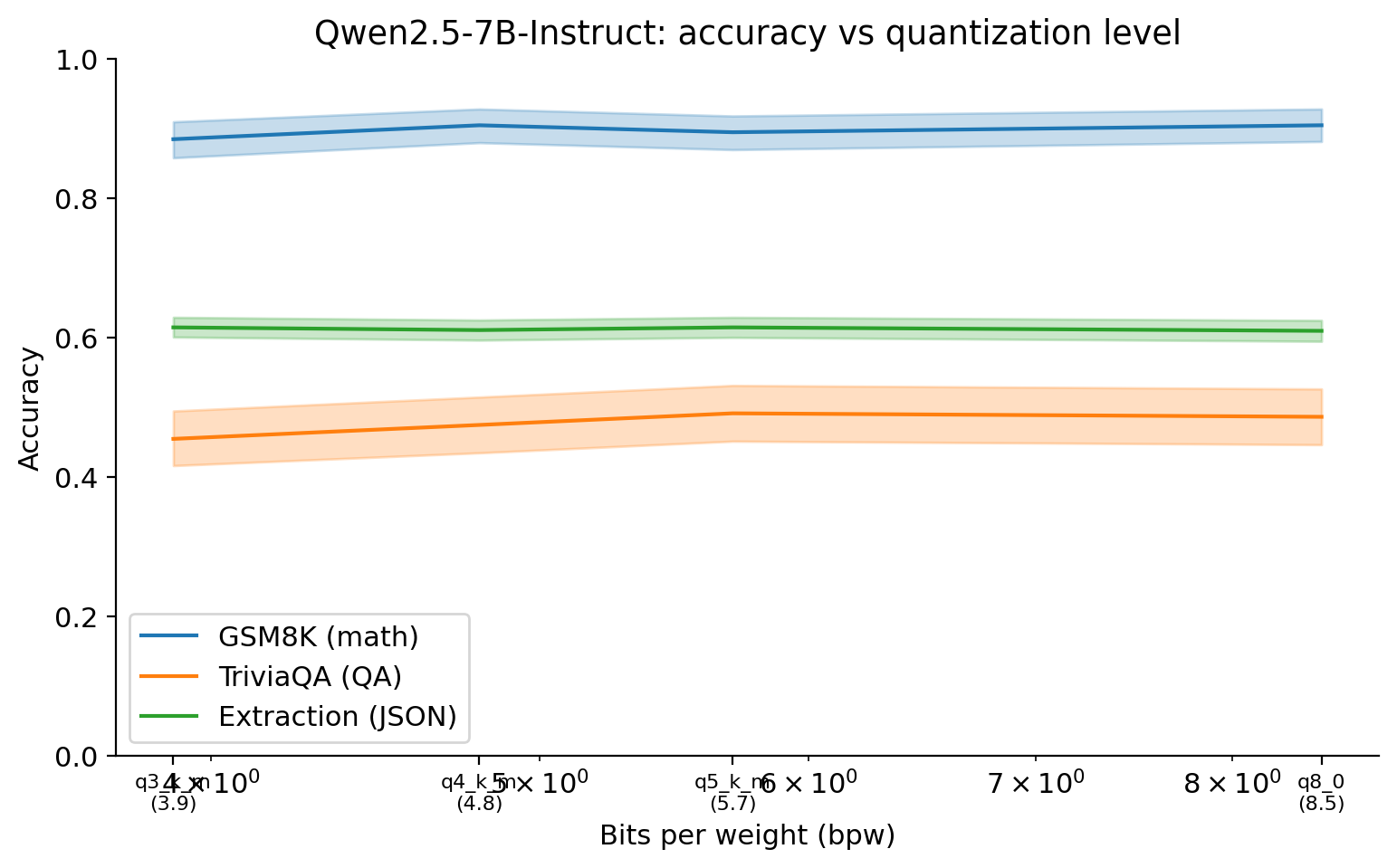
The chart shows accuracy as a function of bits-per-weight for each task, with 95% bootstrap CIs as shaded bands. The most striking feature is how flat two of the three curves are across the tested range.
Key observations from the chart above:
- GSM8K degrades the least, not the most. From Q8_0 (8.5 bpw) to Q3_K_M (3.9 bpw), accuracy moves from 0.905 to 0.885 — a 2pp drop whose CI overlaps zero. The pre-registered prediction that reasoning would cliff first is not supported.
- Extraction is also flat. All four quants score within [0.610, 0.615] on the 3-field JSON grader. JSON generation and constrained-vocabulary fields appear to be robust across the k-quant range, at least for this task type and prompt format.
- The only visible cliff is TriviaQA at Q3_K_M, dropping from 0.487 to 0.455 with a CI that does not overlap Q8_0’s CI. This is the inverse of the hypothesized ordering — factual QA, not math, is what showed the cleanest cliff. One plausible reading: single-pass recall depends on weight precision more than multi-step generation does, because it has no recovery mechanism. But this is post-hoc.
Results — Pairwise Differences (Q8_0 Baseline)
All differences are Q8_0 minus quant-level accuracy; positive values mean Q8_0 is better. 95% CI from 10,000 paired bootstrap resamples (seed=42).
| Quant level | GSM8K diff (95% CI) | TriviaQA diff (95% CI) | Extraction diff (95% CI) |
|---|---|---|---|
| Q5_K_M | +0.010 [−0.010, +0.030], p=0.37 | −0.005 [−0.017, +0.007], p=0.49 | −0.005 [−0.010, +0.000], p=0.051 |
| Q4_K_M | +0.000 [−0.018, +0.018], p=1.00 | +0.012 [−0.007, +0.032], p=0.24 | −0.001 [−0.007, +0.005], p=0.79 |
| Q3_K_M | +0.020 [−0.003, +0.043], p=0.10 | +0.032 [+0.008, +0.057], p=0.011 | −0.005 [−0.013, +0.003], p=0.23 |
p-values are two-sided paired bootstrap (10,000 resamples, seed=42). The only comparison reaching conventional significance for a quality drop is TriviaQA at Q3_K_M (bolded). The Q5_K_M extraction p=0.051 is borderline, but the sign is “Q5 better than Q8” — i.e. noise around a flat curve, not a quantization signal.
Discussion
Did the hypothesis hold?
No. The pre-registered hypothesis predicted that math reasoning would degrade earlier and more sharply than factual QA. The data show the opposite: GSM8K accuracy was the most stable across the quantization range (0.905 → 0.885, no significant pairwise diff), while TriviaQA produced the only statistically significant quality drop (Q3_K_M: −3.2pp, p=0.011). One plausible post-hoc explanation is that chain-of-thought on GSM8K is self-correcting — the model has many opportunities to recover from a slightly noisier weight matrix — whereas single-pass factual recall on TriviaQA fails or succeeds in one shot. But this is speculation; pre-registering it and testing on a different model family is the next step, not a conclusion from this experiment.
The “Q4 is fine” folklore
For Qwen2.5-7B on these tasks, the folklore is approximately right. Q4_K_M is statistically indistinguishable from Q8_0 on all three tasks: GSM8K (diff = 0.000, p=1.00), TriviaQA (diff = +0.012, p=0.24), and structured extraction (diff = −0.001, p=0.79). The drop only becomes detectable at Q3_K_M, and even then only on TriviaQA. That said, “approximately right” carries asterisks: (1) generalization to other model families is untested (see Limitations); (2) at n=600 the experiment can detect drops of roughly 2–3pp — smaller drops cannot be ruled out; (3) the extraction grader scores only the 3 constrained fields, not the free-form requested_action (see Methodology), so this experiment cannot speak to whether quantization affects the quality of generated prose inside structured outputs.
Practical implications
For Qwen2.5-7B-Instruct specifically: Q4_K_M is the obvious operating point on a 16 GB GPU — it gives Q8_0-equivalent quality on all three tasks while freeing ~3 GB of VRAM for context and KV cache. Q3_K_M is risky on factual-recall workloads (the only significant drop showed up there) but appears acceptable on multi-step reasoning and structured extraction. Q5_K_M offers no measurable quality benefit over Q4_K_M on these tasks and costs ~0.6 GB more — there is no reason to prefer it unless you have a workload not covered here. Generalization to other models is the open question this experiment cannot answer; the methodology and harness are designed so the same protocol can be re-run on Llama 3 or Mistral with a one-line config change.
Limitations
One model family. Results are specific to Qwen 2.5 7B Instruct. The quantization sensitivity of Llama 3, Mistral, or Gemma families may differ — their training regimes, architecture choices, and weight distributions are different. Do not generalize this cliff location to other models without measuring.
Three task types. GSM8K, TriviaQA, and structured extraction cover reasoning, retrieval, and instruction-following respectively, but many practically important task types are untested: code generation, summarization, multi-turn dialogue, long-document understanding. The cliff may fall at different places for these.
Greedy decoding only. All inferences used
temperature=0.0. Sampling-based decoding (higher temperature, nucleus sampling) might smooth some cliff effects by averaging across multiple generation paths — or might amplify them. We do not know.n=600 per (quant, task) cell (200 samples × 3 seeds). Sufficient to detect moderate effects but not small ones — effects below ~2 percentage points generally do not reach statistical significance at this sample size. The TriviaQA Q3_K_M drop (−3.2pp, p=0.011) is right at the edge of what this experiment can resolve.
llama.cpp k-quants only. The four quantization formats tested (Q8_0, Q5_K_M, Q4_K_M, Q3_K_M) are all llama.cpp k-quant variants. AWQ, GPTQ, and EXL2 use different compression strategies with different accuracy-size trade-offs. This experiment does not characterize those formats. FP16 was excluded due to VRAM constraints (15 GB model on a 16 GB card).
Extraction graded on 3 of 4 fields. The grader scores
customer_name,issue_category, andurgency— fields with canonical short-string answers. The fourth field,requested_action, is excluded: the gold is a paraphrased prose summary generated by GPT-4o-mini at dataset-build time, with no canonical string for an exact-match grader to target. A semantic-similarity grader (sentence embedding cosine, or an LLM judge) would be needed to score it meaningfully, and is left to follow-up work. This means the extraction result in this writeup speaks to constrained-vocabulary JSON output (categorical and numeric fields), not to free-form generated text inside a JSON envelope.Grader v1 was buggy; results above use grader v2. The initial scorer had two bugs: (a) it called
json.loadson the raw output without stripping the```jsonMarkdown fences the model emitted ~100% of the time at Q5/Q8, and (b) it includedrequested_actionin an exact-match F1, capping every parsed output at 0.75. Both were caught during result review; the grader was fixed and the existing outputs (saved inruns.parquet) were re-graded in place viaregrade_extraction.py— no re-inference required. The pre-fix draft of this writeup reported extraction as “0% across all quants, methodology failure” before the bug was found.
Reproducibility
Config hash: ac355bd9cda73881 (computed by harness.config.hash_config over config.yaml; also stored in results/runs.sqlite alongside each run’s experiment_id="001-quant-cliff").
Git SHA: Tagged release v1.0 (82f1b59). Per-run SHA stored in results/runs.sqlite column git_sha.
Rerun command:
# From repo root — reproduces the full experiment from scratch
# Step 1: Download GGUFs (~21 GB total: Q3_K_M through Q8_0; fp16 excluded)
python models/download_ggufs.py
# Step 2: Generate extraction dataset (~$0.50 OpenAI, one-time)
python experiments/001-quant-cliff/generate_extraction.py
# Step 3: Full inference run (4 quant levels on RTX 4080 Super)
uv run python experiments/001-quant-cliff/run.py
# Step 4: Compute statistics and generate plots
uv run python experiments/001-quant-cliff/analyze.pyThe run is resumable: if interrupted, re-running run.py skips any (config_hash, task_name) combinations already recorded as complete in results/runs.sqlite. It does not re-run completed triples.
GGUF checksums: SHA-256 of each model file recorded in models/SHA256SUMS at download time. Verify with:
sha256sum --check models/SHA256SUMSEnvironment:
# Pinned versions — see pyproject.toml and versions.md
uv pip install -e . # installs exact pinned deps
# llama.cpp commit SHA: see versions.md
# CUDA version: 12.4 (cu124 wheel)