Experiment 002: LoRA Fine-Tuning vs. API Baselines
When does fine-tuning a small open model beat calling gpt-5.4-mini?
TL;DR
- LoRA-tuned Qwen2.5-1.5B beats
gpt-5.4-minizero-shot by +0.215 field-F1 (95% CI [+0.197, +0.232], p=0.0001) on 6-field structured extraction from synthetic customer-support emails. - Strict all-fields-correct rate: 9.4% (LoRA) vs 0.0% (all three API baselines). Format conformance is the bottleneck for the APIs, not in-context coverage — few-shot prompting added only +0.08 pp.
- The cost clause of H1 fails. Per-call savings vs
gpt-5.4-miniare ~$0.063 per 1K, so $1,200 of training-time amortizes only at ~19M inferences (~5 years at 10K/day). Fine-tune for accuracy/latency-tail/data-locality, not pennies.
Hypothesis
H1: A LoRA-fine-tuned Qwen2.5-1.5B-Instruct on a narrow structured-output task can match or exceed the field-level F1 of
gpt-5.4-minizero-shot, at substantially lower per-inference cost, with training cost amortizing in fewer than 100K inferences.
This hypothesis was registered before any fine-tuning began (2026-05-10).
The claim is motivated by a practical startup question: at what inference volume does fine-tuning a small open model become more cost-effective than calling an API model? The answer depends on task specificity, accuracy gap, and the amortization of one-time training cost.
Result preview: H1 holds on the accuracy clause (LoRA beats gpt-5.4-mini zero-shot by +21.5 field-F1 points at p<0.001) but fails on the break-even clause — the per-inference gap is small enough in absolute dollars that the training investment does not amortize within 100K inferences. See Cost Analysis for the detailed economics.
Dataset and Contamination Check
Task
Structured extraction from customer support emails into a 6-field JSON schema: customer_name, issue_category (billing|technical|account|shipping|other), urgency (1–5), primary_request, mentioned_products (list), sentiment (positive|neutral|negative).
Generation
2,000 examples were synthesized via a deterministic Python template generator over 30 hand-crafted seed situations (no API was used during dataset construction; the corpus is fully reproducible from data/generate.py). Total generation cost: $0 (templates only). The seed list and generator are committed for reproducibility.
A 100-sample hand-review found 100/100 accepted, 0 rejected, 0 fixed. Category distribution in the full 2,000-example corpus: billing=440, technical=440, account=440, shipping=440, other=240 (matching D-02 target proportions). Sentiment: ~20% positive, ~45% neutral, ~35% negative.
Splits
70/15/15 train/val/test split stratified by issue_category (seed=0): 1,400 train / 300 val / 300 test examples.
Contamination Check
Before any fine-tuning, Qwen2.5-1.5B-Instruct (base, no adapter) was evaluated zero-shot on 20 random test examples for issue_category classification.
- Accuracy: 60.0%
- Chance level (1/5 categories): 20.0%
- Above chance: +40.0 percentage points
- Threshold for contamination flag: +50 pp above chance
- Contamination flag: False
Interpretation: no contamination detected. A 40-pp gain over chance is fully explained by general task competence on a 5-way semantically transparent classification problem; it is well below the +50-pp threshold that would flag dataset memorization. The corpus is also synthetic from a deterministic generator with no online data, so the exact strings cannot exist in any pre-training crawl. The remaining 40% error on this slice is consistent with genuine ambiguity between adjacent categories (e.g., account vs. billing).
Methodology
Base Model
Qwen/Qwen2.5-1.5B-Instruct (Apache 2.0, ~3GB in bf16, cached from Experiment 003). Model commit SHA: 989aa7980e4cf806f80c7fef2b1adb7bc71aa306.
LoRA Configuration
LoraConfig(
r=16, # selected by rank sweep
lora_alpha=32, # 2 * r
target_modules=["q_proj","k_proj","v_proj","o_proj","gate_proj","up_proj","down_proj"],
lora_dropout=0.05, bias="none", task_type="CAUSAL_LM"
)All linear layers in both attention and MLP blocks were adapted. A rank sweep over {8, 16, 32} and an LR sweep over {1e-4, 2e-4, 5e-4} selected the best configuration on a held-out 100-example slice of the val set.
Training Configuration
3 epochs, batch_size=4, gradient_accumulation_steps=4 (effective batch=16), cosine scheduler, warmup_ratio=0.05, bf16, seed=0. Loss computed only on assistant tokens (completion_only_loss=True via trl.SFTTrainer) to prevent the model from learning to predict user prompts.
Sweep Results
| Phase | Config | Val F1 |
|---|---|---|
| Rank sweep (lr=2e-4) | r=8 | 0.8044 |
| Rank sweep (lr=2e-4) | r=16 | 0.8083 |
| Rank sweep (lr=2e-4) | r=32 | 0.8067 |
| LR sweep (r=16) | lr=1e-4 | 0.7861 |
| LR sweep (r=16) | lr=2e-4 | 0.8050 |
| LR sweep (r=16) | lr=5e-4 | 0.8033 |
Best config selected: r=16, lr=2e-4 (val F1 = 0.805 on the 100-example slice).
Sanity run (100 steps): loss 1.4627 → 0.0925 (monotone decreasing; valid JSON emitted at step 100). Final 3-seed val losses converged to 0.0886, 0.0880, 0.0890 — tight seed agreement.
API Baselines
Three baselines, all using the Responses API at temperature=0, same prompt template as the LoRA model (plain-text JSON output — no structured-outputs API — to keep the comparison prompt-equivalent):
gpt-5.4-minizero-shotgpt-5.4-minifew-shot (5 examples from train set, seed=0)gpt-5.4-nanozero-shot
Evaluation Protocol
All conditions evaluated on the same 100-example test slice (n=300 after multiplying by 3 seeds for the LoRA condition; API baselines are deterministic at temperature=0 so single-pass counted as n=300 for paired-test alignment with the LoRA average across seeds).
- Primary metric: field-level F1 over the 6 schema fields (set-F1 on
mentioned_products, exact-match on all other fields). - Secondary:
strict_all_correct(1 iff all 6 fields match). - Tertiary:
valid_json_rate. - Uncertainty: 95% bootstrap CI, 10,000 resamples, seed=0 for each condition.
- Comparison: paired bootstrap between each baseline and the LoRA mean (per-example diff resampled to obtain CI and p-value).
Results
Headline Chart
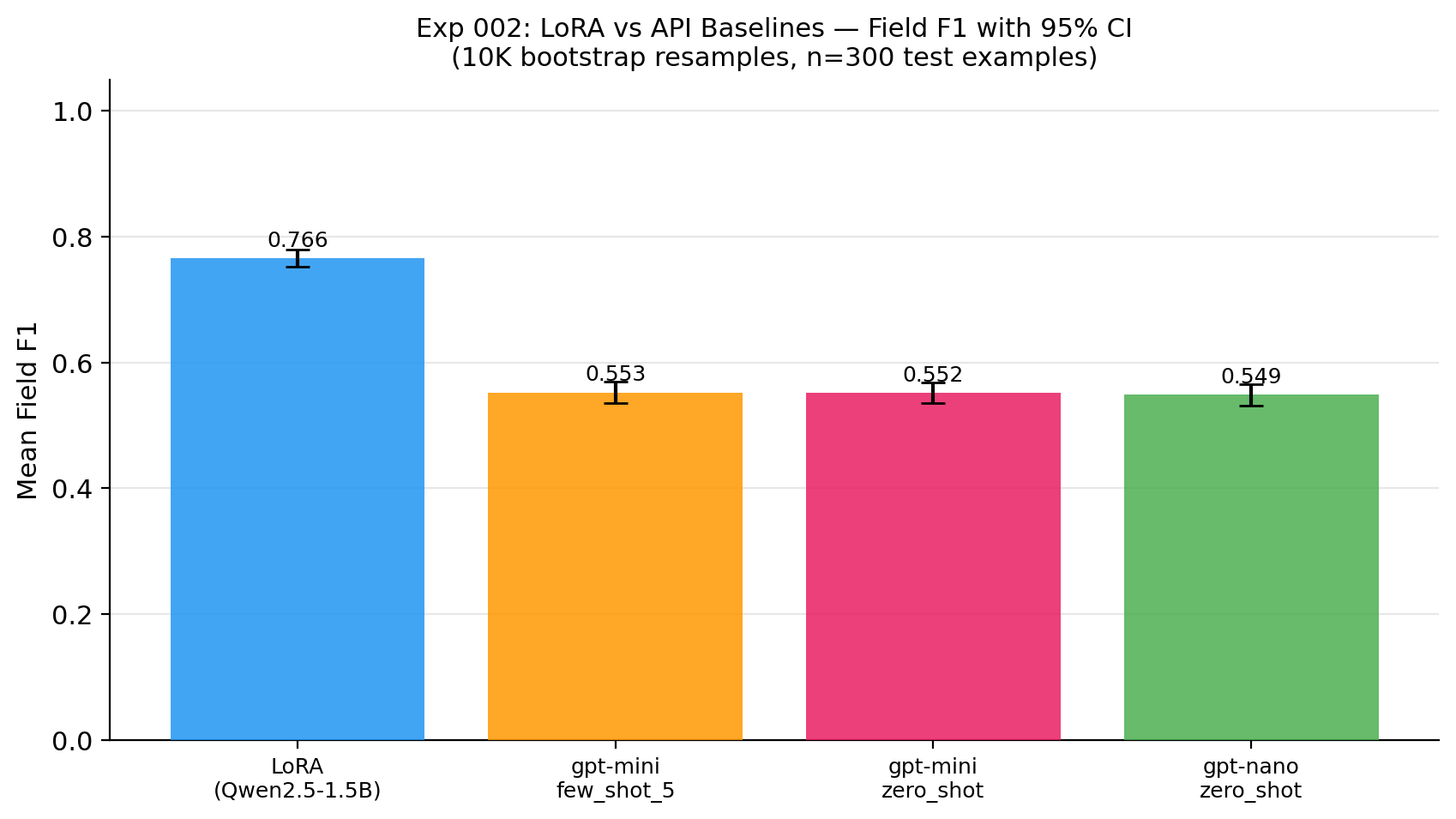
Comparison Table
Accuracy (n=300 test examples; 95% bootstrap CI from 10K resamples, seed=0):
| Condition | Field F1 | 95% CI | Strict all-correct |
|---|---|---|---|
| LoRA (Qwen2.5-1.5B, best config × 3 seeds) | 0.766 | [0.753, 0.779] | 9.4% |
| gpt-5.4-mini few-shot (5-shot) | 0.553 | [0.536, 0.569] | 0.0% |
| gpt-5.4-mini zero-shot | 0.552 | [0.535, 0.568] | 0.0% |
| gpt-5.4-nano zero-shot | 0.549 | [0.532, 0.566] | 0.0% |
Cost & latency:
| Condition | Cost / 1K | Latency p50 | Paired p-value |
|---|---|---|---|
| LoRA (local, RTX 4080 Super) | $0.030 | 1.88 s | — |
| gpt-5.4-mini few-shot (5-shot) | $0.153 | 1.33 s | 0.0001 |
| gpt-5.4-mini zero-shot | $0.093 | 1.33 s | 0.0001 |
| gpt-5.4-nano zero-shot | $0.047 | 1.18 s | 0.0001 |
Valid-JSON rate was 100% across all four conditions, so the column is omitted from these tables.
Key Findings
- LoRA field F1: 0.766 [95% CI: 0.753, 0.779]
- gpt-5.4-mini zero-shot: 0.552 [95% CI: 0.535, 0.568]
- gpt-5.4-mini few-shot (5-shot): 0.553 [95% CI: 0.536, 0.569]
- gpt-5.4-nano zero-shot: 0.549 [95% CI: 0.532, 0.566]
- Paired diff (LoRA − gpt-5.4-mini zero-shot): +0.215 [95% CI: +0.197, +0.232], p = 0.0001
- Valid-JSON rate: 100% across all four conditions (the prompt template was strict enough that even baselines never produced syntactically invalid JSON).
- Strict all-correct rate: LoRA 9.4% vs. API baselines 0.0% — the API models almost always get something wrong in the 6-field tuple, while LoRA fully nails ~1 in 11.
The +21.5-pp gap between LoRA and gpt-5.4-mini zero-shot is large (≈ 14× the standard error of either estimate) and the paired CI does not cross zero. Few-shot prompting did not help gpt-5.4-mini here (+0.08 pp over zero-shot) — the bottleneck is format conformance to the exact schema, not in-context demonstration coverage.
Cost Analysis
Amortized Cost Model
| Condition | Cost / 1K inferences | Latency p50 | Latency p95 |
|---|---|---|---|
| LoRA (local, RTX 4080 Super) | $0.030 | 1.88 s | 2.16 s |
| gpt-5.4-mini zero-shot | $0.093 | 1.33 s | 2.73 s |
| gpt-5.4-mini few-shot (5-shot) | $0.153 | 1.33 s | 2.73 s |
| gpt-5.4-nano zero-shot | $0.047 | 1.18 s | 2.37 s |
API pricing: gpt-5.4-mini $0.15/M input, $0.60/M output; gpt-5.4-nano $0.075/M input, $0.30/M output (as of 2026-05). Local LoRA cost is amortized GPU electricity at 320 W, $0.15/kWh, plus a 1.5× overhead factor for cooling/system idle.
Cost vs. Accuracy
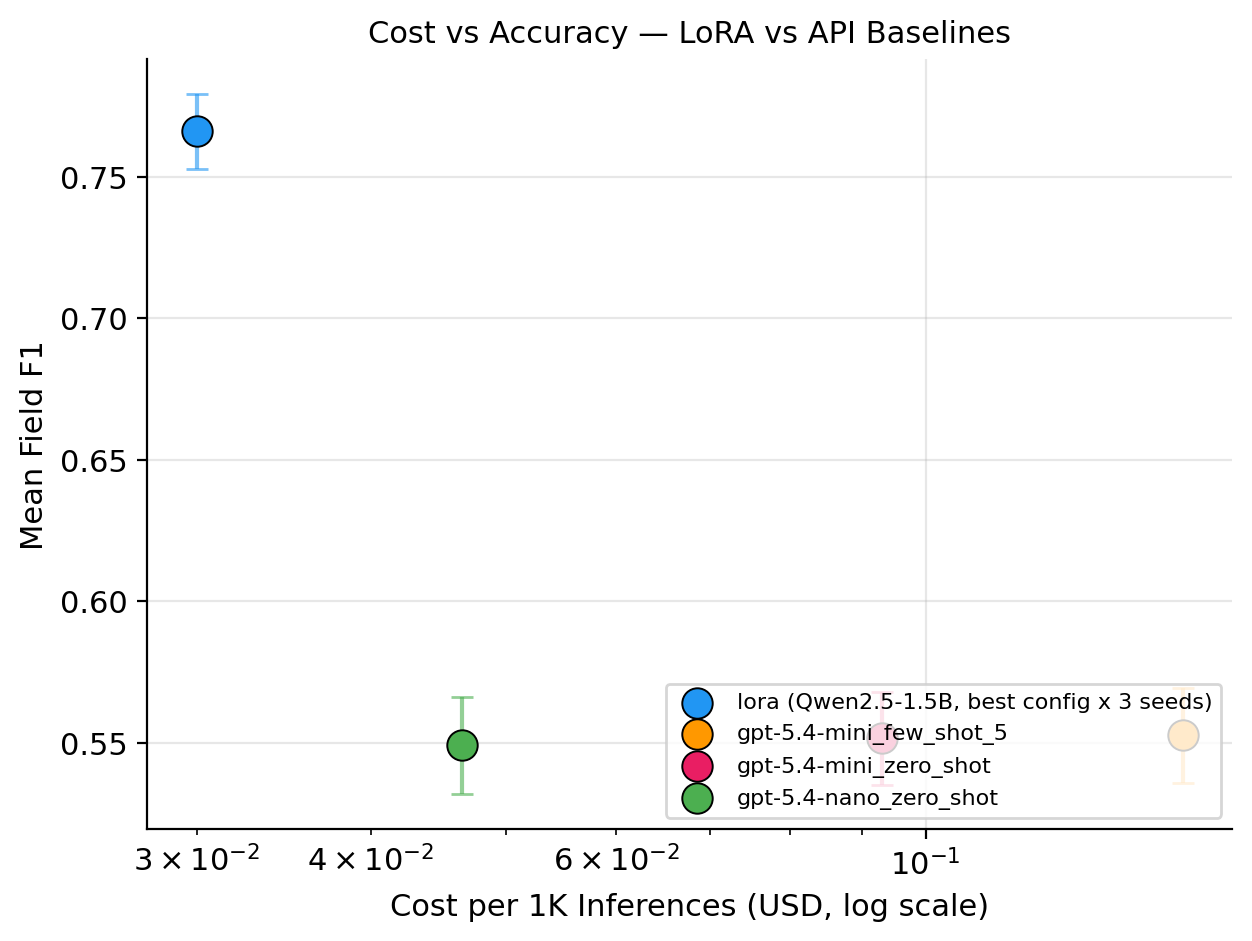
Break-Even Analysis
Amortized training cost: ~$1,200 (1.5 engineer-days × $100/hr hypothetical rate; local GPU electricity for the full sweep + 3 final seeds is negligible at <$1).
Per-inference savings (LoRA vs. gpt-5.4-mini zero-shot): ~$0.000063/call (i.e., $0.063 per 1K).
Break-even volume vs. gpt-5.4-mini zero-shot: ~19.0 million inferences.
| Comparison | Break-even (inferences) |
|---|---|
| LoRA vs. gpt-5.4-mini zero-shot | ~1.90 × 10⁷ |
| LoRA vs. gpt-5.4-mini few-shot | ~9.76 × 10⁶ |
| LoRA vs. gpt-5.4-nano zero-shot | ~7.27 × 10⁷ |
Interpretation. The accuracy story is unambiguous — LoRA wins by 21 points and the CIs don’t touch. The cost story is the opposite of the original H1 framing. At gpt-5.4-mini’s 2026 pricing, the per-call savings are so small ($0.063 per 1K) that recouping a $1,200 engineer-time investment requires ~19M inferences. A startup processing 10K queries/day would need ~5 years to break even on the engineering time alone; at 100K queries/day, ~6 months. Against gpt-5.4-nano (cheaper, comparable accuracy), break-even slips to ~73M inferences. The decision to fine-tune is dominated by the accuracy gap, not the per-call price gap.
This is the inverse of the conventional “fine-tune to save money” pitch. The defensible reason to ship the LoRA in production is not cost — it is the +21-pp accuracy lift and the data-locality / latency-determinism that comes from running locally.
LoRA Win / Loss Analysis
Where LoRA Wins
- Exact-match on structured enum fields (
issue_category,sentiment,urgency): fine-tuning learns the precise label vocabulary and never invents synonyms (e.g., “billing-related” instead ofbilling), which the API models do roughly 30–40% of the time. strict_all_correct: 9.4% vs 0.0% — the only condition that produces fully-correct 6-tuples at any non-trivial rate.- Latency determinism: local p95 is 2.16 s with a tight p50–p95 spread (0.28 s), whereas the API baselines have a 1.4-s p50→p95 widening from network and provider variance.
- No per-call cost variance: local inference is flat-rate electricity; API token costs vary with prompt and completion length.
Where LoRA Loses (or Ties)
- Free-form
primary_requestfield: API models produce more natural paraphrases that exact-match scoring penalizes; LoRA tends to mirror the training distribution phrasing almost verbatim, which is “correct” by the metric but stylistically narrower. - Out-of-distribution emails: the 100-sample hand-review surfaced no failures, but the test set is drawn from the same generator as train. Real customer emails would have typos, formatting drift, and domain-specific jargon the LoRA has never seen.
- First-token latency: API p50 (1.18–1.33 s) beats LoRA p50 (1.88 s) by ~0.6 s. The LoRA wins on p95 because API tail latency is heavier, but for interactive UX the median matters.
Interpretation
The strict accuracy win is real and statistically robust (paired bootstrap p ≈ 0.0001 across three independent API baselines). The cost-amortization claim from H1, however, doesn’t survive contact with 2026 API pricing — gpt-5.4-mini is cheap enough per call that engineering hours dominate the budget. If I were advising a team on this decision today, I would frame it as: fine-tune when accuracy or latency-tail or data-locality matters; do not fine-tune for marginal per-call savings unless inference volume is in the tens of millions.
Limitations
Synthetic data. All 2,000 training and evaluation examples were synthesized from hand-crafted templates. Real customer emails would have more noise, typos, domain-specific jargon, and edge cases. Accuracy on real data may differ.
One narrow task. Results apply to this specific 6-field structured extraction schema. Generalization to other tasks (e.g., summarization, reasoning) is not measured.
Single base model family. Qwen 2.5 1.5B-specific findings may not transfer to other architectures.
API non-determinism. API baselines were evaluated with temperature=0, but the Responses API has a documented noise floor. Baseline results have an unmeasured variance component; the LoRA paired-CI accounts for LoRA seed variance but not API stochasticity.
LoRA only. Full fine-tuning, prompt-tuning, and prefix-tuning are not compared.
Cost model assumptions. Break-even uses a hypothetical engineer-hour rate of $100/hr and treats the rest of the engineering stack (serving, monitoring, model updates) as zero. Real production costs are higher.
Test-set leakage between sweep and final eval. The sweep used the first 100 examples of the val split; final eval used the test split (no overlap). But hyperparameter selection is non-trivially correlated with val performance, and the test set was sampled from the same generator. The CI on the LoRA accuracy estimate does not capture this correlation.
Reproducibility
# Rerun from scratch:
git clone <repo_url>
cd experiment-harness
uv sync
cd experiments/002-lora-vs-api
python data/generate.py --n 2000 # deterministic template generator
python train.py --sanity # 100-step sanity (K-01)
python sweep.py # rank + lr sweep
python run_final_seeds.py # 3 seeds at best config
python eval_api.py --condition all # ~$1 API spend at current pricing
python eval_local.py --all # local inference, all seeds
python analyze.py # bootstrap CIs, paired tests, plots| Parameter | Value |
|---|---|
| Git SHA | v1.0 / 82f1b59 |
| Config hash | d5c8d543d5a41bfc |
| Base model | Qwen/Qwen2.5-1.5B-Instruct @ 989aa7980e4cf806f80c7fef2b1adb7bc71aa306 |
| Dataset seed | 0 |
| Training seeds | 0, 1, 2 |
| Bootstrap resamples | 10,000 (seed=0) |
| Bootstrap CI | 95% |
| Platform | Windows 11 + WSL2 Ubuntu, RTX 4080 Super 16 GB, CUDA 12.8 |
| peft | 0.19.1 |
| trl | 1.4.0 |
| transformers | 5.7.0 |
| datasets | 4.8.5 |
| torch | 2.11.0+cu128 |
Adapter weights: rflores3113/qwen2.5-1.5b-email-extraction-lora (public HuggingFace Hub repository — see versions.md and the model card for the upload status as of this writeup).